
Cloud
Simplify Cloud Operations for Large Supermarket Chains
Simplify Cloud Operations for Large Supermarket Chains Through a transition from GCP (Google Cloud Platform) to Amazon Web Service, a leading supermarket operations firm efficiently

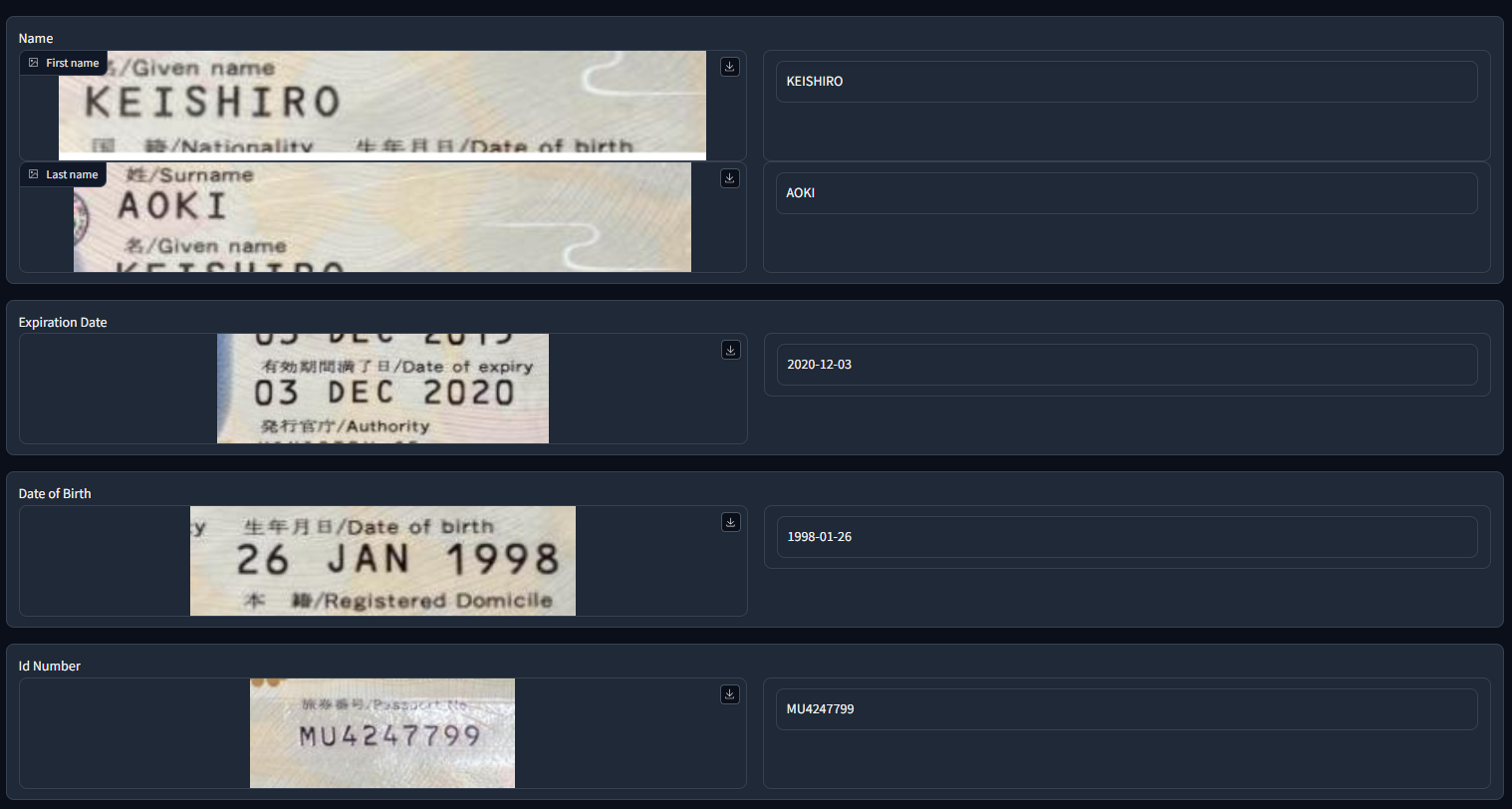
To assist the client in verification, Rikkei AI developed an information extraction tool that can recognize and pull information from pictures of ID documents. After receiving input from users (document photos), the tool will first classify the pictured document into “card” and “paper” categories based on the physical properties shown. It will then standardize the document if necessary by resizing and/or rotating the images.
After standardization, the tool uses Microsoft’s Azure Optical Character Recognition Cognitive Service to detect text fields in the document. These text fields then go through Rikkeisoft’s own fine-tuned Large Language Model (similar to that of OpenAI’s) for information extraction. This LLM is capable of dealing with over 100 languages, including Japanese, Chinese and Korean.
When the tool has finished with extraction, it continues to the verification step. Depending on the type of document, this is done through either photo or ID number verification.
Simplify Cloud Operations for Large Supermarket Chains Through a transition from GCP (Google Cloud Platform) to Amazon Web Service, a leading supermarket operations firm efficiently

Complete eCommerce marketplace solutions for large shopping mall About the Client Web development Mobile App This article describes a real-life project. However, we cannot disclose
eCommerce website for B2B corporate buyers About the Client Web development Mobile App This article describes a real-life project. However, we cannot disclose our client’s